[SpringBoot] Spring Batch
Why?
내가 맡고 있는 서비스인 오피스 업무개선 제안으로 대용량 처리 관련해서 이야기가 많이 나왔었다. 대용량 처리에 대한 기술들을 찾다가 배치라는 것을 알게되었다. 배치에 대한 개념이 없었기에 궁금해서 관심을 가지게 되었다.

그중에서도 ‘‘스프링 배치’‘를 읽게된 것은 현재 주력으로 사용하고 있는 기술 스택이기 때문에 비교적 최근에 출판된 스프링 배치 완벽 가이드 2/e 라는 책을 찾아 읽게되었다.
1장~3장의 경우 배치가 어떤거고 스프링 배치에 전반적인 내용들과 가벼운 예시였고, 4장 ~ 10장은 각각의 기능들의 개념/사용법 (튜토리얼)및 예제를 소개하고 있다. 완전하게 습득된게 아니라서 아래와같이 블로그를 나눠 포스팅하려고 한다.
- 전반적인 요약 및 오피스 내 적용해볼 만한 점들 생각
- 각 기능들의 세부사항들을 정리
- ToyProject수준의 간단한 예제 및 의미있는 결과
Contents
이번 포스팅의 목차는 아래와 같다.
- Spring Batch 개념
- 우리 서비스에 적용해 볼 점
Spring Batch 개념
Batch?
배치(Batch)는 일괄처리라는 뜻을 가지고 있다.
은행에서 생성되는 거래명세서와 퇴직 연금 명세서는 모두 배치 처리를 이용해 생성된다고 한다. 아마존(Amazon)과 같은 사이트에서 연관 상품을 추천하는 데이터 과학 모델도 배치처리로 생성되고있고, 쇼핑몰 등 이커머스쪽에서 대량의 이메일을 보낼 때 배치 처리를 통해 전송 되었을 것이라 추측한다.
매일 전날의 데이터를 집계한다고 가정했을 때, 어디에서 처리하는 것이 좋을까? 보통은 현재 서비스 중인곳에서 처리하게 될 것이다. 그러나 현재 서비스 중인 애플리케이션에서 큰 데이터를 조회, 가공, 저장한다면 해당 서버는 순식간에 CPU, I/O등의 자원을 다 써버리게 될 것이다.
그리고 보통 이러한 집계는 하루에 1번 정해진 시간에 처리해야하는 경우가 많다. 이 부분을 실행하기 위해서 하루중 언제라도 수행해도 되겠지만 사용자들이 가장 적게 사용하는 시간대에 수행하는 것이 가장 유리할 것이다. 그 외 배치를 처리하기 위한 보안 기술도 고려해야하며, 실패나 재실행에 대한 모든 부분을 개발해야 할 것이다.
이렇게 배치 시스템을 만들기 위해서는 기술적으로 처리해야할 부분이 너무나 많다는 점이다.
이러한 단발성의 대용량 데이터를 처리하는 애플리케이션을 배치 애플리케이션이라고 한다. Spring 진영에서는 이러한 배치 애플리케이션을 구성하기 위한 모듈을 지원하는데, 이것이 Spring Batch이다.
Spring Batch?
이미 위에서 잠깐 언급이 되었지만 배치를 직접 구현해야 한다면 일단 기술적으로 개발자가 처리해야 할 부분이 상당히 많다. 또한 현재 서비스중인 애플리케이션에서 배치를 수행한다면 분명 리소스 부족을 경험하게 될 것이다. 이러한 부분에 대한 고려를 줄이고 아래 장점들을 비롯해 비지니즈 로직에 집중할 수 있도록 한 것이 스프링 배치이다.
- 유지보수성 : 스프링 배치의 경우 트랜잭션 및 커밋 횟수와 같은 것들을 애플리케이션에 제공하므로 처리가 어디까지 진행됐는가라던지 실패 시 무슨 일을 해야 하는지 관리할 필요가 없다.
- 유연성 : 메인 프레임에선 코볼을 사용하거나 고객 정보 제어 시스템(CICS)를 사용하는 것이 전부이다. 유닉스 계열에서는 C++이 있긴 하나 마땅한 프레임워크가 없어 환경에 맞춰 일일이 개발해야 한다. 이런 부분들을 JVM의 유연성으로 해결할 수 있다. 또한 시스템 간 코드를 공유할 수 있는 유연성도 제공한다. 이미 테스트 및 디버깅 된 서비스를 배치 처리에서 동일하게 바로 사용할 수 있다.
- 확장성 : 대부분 메인 프레임에서는 확장성을 위한 용량 증설이 제한된다. 병렬로 작업을 수행하는 방법은 보통 단일 하드웨어 내에서 전체 프로그램을 병렬로 실행하는 것이다. 이 방식은 병렬 처리용 코드를 작성하고 유지 보수해야하며, 이로 인한 오류 처리나 상태 관리등의 어려움을 겪을 수 있다. 그러나 스프링 배치의 경우 단일 서버 내의 단일 JVM에서 배치 처리도 가능하고 사업이 확장됨에 따라 여러개의 노드로 나눠 완료할 수 있으며 클라우드 리소스를 사용해 확장해 나갈 수 있다.
Spring Batch Application
스프링 배치 프레임워크는 크게 세 가지 레이어로 구성되어 있다.
- application layer : 개발자가 개발한 코드, 대부분 코어 레이어와 상호작용한다.
- core layer : 배치 영역을 구성하는 실제적인 여러 컴포넌트이다.
- Infrastructure layer : ItemReader, ItemWriter를 비롯해 재시작과 관련된 문제를 해결할 수 있는 클래스와 인터페이스를 제공한다.
Core layer를 기준으로 배치 처리 아키텍처를 살펴보면 아래와 같다.
잡과 스텝
잡(Job) : ‘상태를 수집하고 이전 상태에서 다음 상태로 전환된다.’(????) 라고 책에 쓰여 있지만 이해하기가 어려웠다. 읽어보면서 이해한대로 좀 풀어서 설명을 해보면, 하나의 배치 작업 단위라고 생각하면 된다. Spring Batch가 해야할 작업 중 가장 큰 범위이며, 보통 Job 안에는 여러 Step이 존재한다.
스텝(Step) : ‘스프링 배치에서 가장 일반적으로 상태를 보여주는 단위이다. 각 스텝은 잡을 구성하는 독립된 작업의 단위이다. 스텝에는 Tasklet, Chunk 기반으로 2가지가 있다.’(????) 라고 쓰여있지만 이 또한 이해하기가 참 어렵다. 설명을 덧붙여 보자면 Job보단 작은 단위의 배치 작업 단위이고 이 Step안에는 Tasklet과 Reader & Processor & Writer 묶음(chunk)이 존재한다.
- Tasklet
- 스텝이 중지될 때까지 execute 메서드가 계속 반복해서 수행된다.
- execute 메서드를 호출할 때마다 독립적인 트랜잭션이 얻어진다.
- 초기화, 저장 프로시저 실행, 알림 전송과 같은 잡에서 일반적으로 사용된다.
- Chunk
- 아이템 기반의 처리에 사용된다.
- 각 Chunk 기반 스텝은 ItemReader, ItemProcessor, ItemWriter 라는 3개의 주요 부분으로 구성될 수 있다.
- ItemProcessor 은 필수가 아니다.
Tasklet 하나와 (Reader & Processor & Writer) 한 묶음이 같은 레벨이다. Tasklet은 어찌보면 Spring MVC의 @Component, @Bean과 비슷한 역할이라고 봐도 될 것 같다. 명확한 역할은 없지만, 개발자가 지정한 커스텀한 기능을 위한 단위로 보면 된다.
위에 정의된 내용과 설명들을 봐도 감이 잘 잡히지 않을 수 있다. 아래 간단하게 작성한 소스를 통해 잡과 스텝이 어떤건지 이해하고 넘어가면 좋을 것 같다.
@RequiredArgsConstructor
@Configuration // Spring Batch의 모든 Job은 @Configuration으로 등록해서 사용
public class BatchApplication {
Logger logger = LoggerFactory.getLogger(getClass());
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job testJob() {
// JobBuilderFactory 클래스의 get() 메서드로 JobBuilder를 생성할 수 있다.
// 이렇게 생성된 JobBuilder로 Job을 생성한다.
return jobBuilderFactory.get("testJob") // testJob이란 이름의 Batch Job을 생성
.start(testStep1()) // testStep1을 실행하겠다라는 의미
.next(testStep2()) // testStep2 실행
.build();
}
// 순차적으로 Step들 연결시킬때 사용한다.
// 아래 step은 logger.info()의 내용을 출력하는 일을하고 있다.
@Bean
public Step testStep1() {
// testStep1이란 이름의 Batch Step을 생성, Builder를 통해 이름을 지정
return stepBuilderFactory.get("testStep1")
.tasklet((contribution, chunkContext) -> { // Step 안에서 수행될 기능들을 명시
logger.info(">>>스텝11111!!!"); // 출력 내용
return RepeatStatus.FINISHED; // Tasklet이 완료되었음을 스프링 배치에게 알림
})
.build();
}
@Bean
public Step testStep2() {
return stepBuilderFactory.get("testStep2")
.tasklet((contribution, chunkContext) -> {
logger.info(">>>스텝22222!!!");
return RepeatStatus.FINISHED;
})
.build();
}
}
step1 -> step2)

step2 -> step1)

Job의 경우 코드가 거의 없는 것을 볼 수 있다. Step은 실제 Batch 작업을 수행하는 역할을 하며 구체적으로는 Batch로 실제 처리하고자 하는 기능과 설정을 모두 포함하는 장소라고 생각하면 좀 더 이해하기 좋을 것 같다.
잡 또는 스텝 실행
- JobInstance
- 스프링 배치 잡의 논리적인 실행이다.
- 하루에 한 번씩 배치의 Job이 실행된다면, 각각의 Job을 JobInstance라고 부를 수 있다.
- JobInstance 는 여러개의 JobExecution 을 가질 수 있다.

- JobExecution
- 스프링 배치 잡(Job)의 실제 실행을 의미한다.
- 잡을 구동할 때마다 매번 새로운 JobExecution 을 얻게된다.

- StepExecution
- 스프링 배치 스텝(Step) 의 실제 실행을 의미한다.

-
JobRepository
-
다양한 배치 수행과 관련된 수치 데이터(시작 시간, 종료 시간, 상태, 읽기/쓰기 횟수 등)와 잡의 상태를 유지 및 관리한다.
-
일반적으로 관계형 데이터베이스를 사용하며 스프링 배치 내의 대부분의 주요 컴포넌트가 공유한다.
-
실행된 스텝, 현재 상태, 읽은 아이템 및 처리된 아이템 수 등이 모두 JobRepository 에 저장된다.
-
어떤 Job이 실행되었고, 몇 번 실행되었고 또 언제 끝났는지등 배치 처리에 대한 메타데이터를 저장한다.
ex) Job 하나가 실행되면 JobRepository에서는 배치 실행에 관련된 정보를 담고 있는 도메인인 JobExecution을 생성한다.
-
-
JobLauncher
- 잡을 실행하는 역할을 담당한다. Job.execute 을 호출하는 역할이다.
- 잡의 재실행 가능 여부 검증, 잡의 실행 방법(현재 thread에서 수행할 지 thread pool을 통해 실행할지), 파라미터 유효성 검증 등을 수행한다.
- JobLauncher는 Job, JobParameters와 함께 배치를 실행하는 인터페이스이다.
- run() 메서드 하나만 가진다. ex) JobExecution run(Job job, JobParameters jobParameters);
- 잡을 실행하면 해당 잡은 구성된 목록에 따라 각 스텝을 실행한다. 각 스텝이 실행되면 JobRepository는 현재 상태로 갱신된다.
위에 정의된 내용으로 봐선 이해하기가 어렵다. 아래 그림과 소스를 통해 차근차근 이해해보자.
@RequiredArgsConstructor
@Configuration // Spring Batch의 모든 Job은 @Configuration으로 등록해서 사용
public class BatchApplication {
Logger logger = LoggerFactory.getLogger(getClass());
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job testJob() {
return jobBuilderFactory.get("testJob")
.start(testStep1(null))
.build();
}
@Bean
@JobScope
public Step testStep1(@Value("#{jobParameters[paramDate]}") String paramDate) {
return stepBuilderFactory.get("testStep1")
.tasklet((contribution, chunkContext) -> {
logger.info(">>>스텝11111!!!");
logger.info(">>>paramDate = {}", paramDate);
return RepeatStatus.FINISHED;
})
.build();
}
}

JobInstance는 Job Parameter에 따라 생성되는 내용이다. 이때 Job Parameter는 Spring Batch가 실행될때 외부에서 받을 수 있는 파라미터이다. 예를 들어, 위 소스에서와 같이 어떤 특정 요청 날짜를 Job Parameter로 넘기면 Spring Batch에서는 해당 날짜 데이터로 조회/가공/입력 등의 어떠한 작업을 할 수 있다. 같은 Job 이라도 Job Parameter가 다르면 JobInstance에 기록되며, Job Parameter가 같다면 기록되지 않는다.
JobExecution은 JobInstance와 별로 다르지 않다. 한번에 이해할 수 있을 만한 좋은 내용이 있어 인용을 하자면, JobExecution과 JobInstance는 부모-자식 관계로 보면 이해하기가 쉬울 것 같다. JobExecution은 자신의 부모 JobInstance가 성공/실패했던 모든 내역을 갖고 있다.
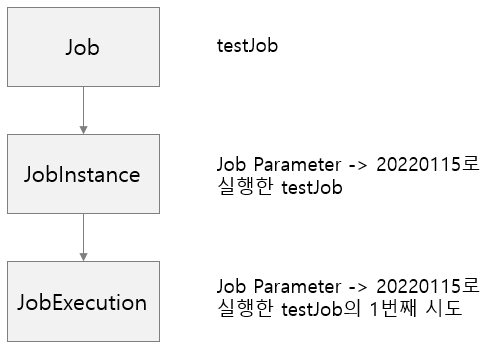
좀 더 쉽게 설명을 하자면, 오늘 Job을 실행했는데 실패했다면 다음날 동일한 JobInstance를 가지고 다시 실행하게 된다.(Job 실행이 실패하면 JobInstance가 끝난 것으로 간주하지 않기 때문이다.) 그렇게되면, 하나의 JobInstance는 어제 실패한 JobExecution과 오늘의 성공한 JobExecution 두 개를 가지게 된다. 즉, 하나의 JobInstance는 여러 개의 JobExecution을 가지게 된다.
우리 서비스에 적용해 볼 점

책을 읽고 간단하게 요약해서 정리해 본 내용들은 위와같다. 단순히 궁금증을 해결하기보단 우리 서비스(오피스)에선 스프링 배치를 왜 써야할지 그리고 어떠한 점을 기대해 볼 수 있는지 개인적으로 생각한 부분을 공유하려고 한다.
오피스에선 왜 굳이 스프링 배치를 써야할까?
- 일단, 현재 오피스의 주요 기술 스택은 자바와 스프링이다. 프레임워크에 대한 기본적인 지식과 경험을 가지고 있기 때문에 도입할 때 큰 부담이 없을것이라 생각했다.
- 스프링 배치의 경우, 자바의 특성인 WORA(Write Once, Run Anywhere)라는 유연성이란 장점이 있고, 스프링 프레임워크의 추상화등을 통해 유지보수성이 높다는 장점이 있다. 각각의 장점을 사용할 수 있는 스프링 배치를 활용한다면 서비스에 좋을것이라 막연하게 생각해 보았다.
- 마지막으로 오피스에선 매일 다량의 로그와 통계, 상품의 상태 변경이 이루어지고 있고, 매일 12시간씩 돌고있는 수십개의 대용량의 스케줄 잡들이 있다. 스프링 배치의 경우, 앞서 정리한 내용과 같이 대용량 처리에 특화되어 있기 때문에 오피스에 이러한 처리들에 대해 현재보다 더 나은 성능을 기대해 볼 수 있다고 생각했다.
구체적으로 어떠한 점을 기대해 볼 수 있을까?
-
현재 오피스에선 대용량을 처리하는 스케줄이 매일같이 돌고 있다. 이러한 스케줄을 스프링 배치를 통해 스텝으로 분리해 볼 수 있을것이라 생각한다. 구체적인 예시를 들어보면 아래와 같다.
-
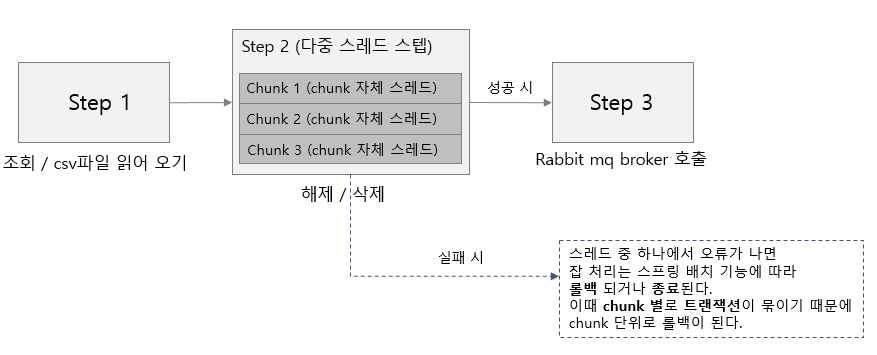
예시1) 한 스케줄을 예시로 들어보자. 간단하게 스케줄에 대해 설명을 해보자면 등록된 A사, B사의 데이터를 조회, 해당 데이터를 통해 타사의 데이터 파싱, 파싱된 데이터로 업데이트하는 구조의 비동기 스케줄이 있다. 해당 스케줄의 경우, 실패 시 전체 재실행되는 스케줄이다.
등록된 A사의 데이터 조회와 B사의 데이터를 따로 조회할 수 있다는 생각이 들었다. 그렇다면 조회하는 부분을 분리해서 조회를 해오게 된다면, 그 이후의 파싱하고 저장하는 부분까지 하나의 스텝으로 묶어 서로 연관없이 진행될 수 있을 것 같다는 생각이 들었다.
스프링배치의 경우, 스텝을 동시에 실행 시킬 수 있기 때문에 각각의 분리된 스텝으로 진행하게 된다면, 전반적인 처리 성능을 높일 수 있지 않을까라는 생각을 했다. 또한 오류 이후 재실행 시 각각의 스텝별로 수동실행이 가능하지 않을까 라는 생각이 들어 아래와 같이 그려보게 되었다.

-
작년 하반기에 대용량의 데이터를 일괄로 삭제하는 작업을 진행한적이 있었다. 해당 이슈의 경우, 운영중인 서비스에 문제가 될 수 있어 몇일에 나눠 진행을 했었다. 이때의 작업을 스프링 배치에 위임하여 진행했다면 서비스 중인 애플리케이션에 영향을 주지 않고, 더 빠른 결과를 도출해 낼 수 있지 않을까 생각했다. 구체적으로 그려본 예시는 아래와 같다.
-
예시2) 필요에 따라 chunk의 사이즈를 더욱 키울 수 있고, 더 많은 스레드로 확장시켜 돌리게 된다면 처리 성능이 오를 수 있지 않을까 싶다.
글을 마치며,,
위에 적용해볼 만한 점은 지극히 개인적인 생각이라 막상 진행해보면 예상한것 만큼 좋은 결과를 도출해내기 어려울 수도 있고, 틀린 방향으로 나갈수도 있다. 그러나 많은 부분에서 개선을 앞두고 있는 이 시기에 한번쯤 다같이 고민해보면 좋을것 같아 글을 작성하게 되었다.
